數據湖 劍指下一代數據處理服務的數據倉庫革新者
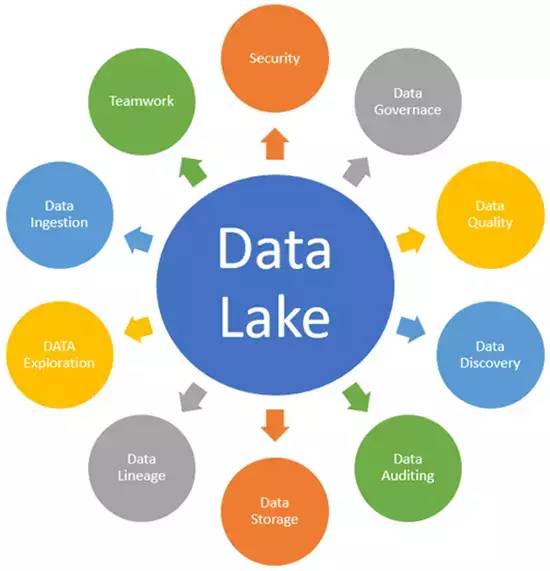
在數字化轉型浪潮中,數據已成為驅動企業決策與創新的核心資產。傳統數據倉庫因其嚴謹的結構化模型和歷史積淀,在穩定報告和商業智能分析方面功不可沒。面對海量、多源、高速的異構數據(如日志、IoT傳感器數據、社交媒體流、圖像視頻),其固有的模式寫入(Schema-on-Write)范式顯得力不從心,流程僵化且成本高昂。正是在此背景下,數據湖(Data Lake) 應運而生,以其開放、靈活和可擴展的特性,正被業界視為劍指下一代數據倉庫的顛覆性架構,并重塑著數據處理服務的格局。
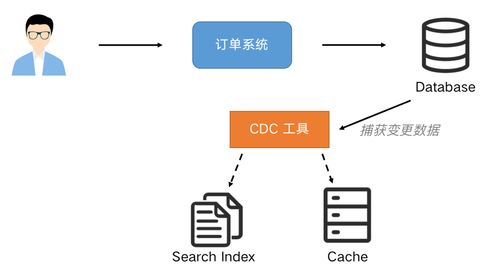
數據湖的核心思想是“先存儲,后處理”。它將來自各種源頭(包括結構化、半結構化和非結構化數據)的原始數據,以其原生格式不加處理或僅進行最低限度的轉換,集中存儲在一個可大規模擴展的存儲庫中(通常基于對象存儲如Amazon S3、Azure Data Lake Storage或HDFS)。這種模式讀取(Schema-on-Read) 的方式,賦予了數據前所未有的靈活性。業務用戶、數據科學家和分析師可以按需訪問原始數據,根據具體的分析場景定義數據結構和轉換邏輯,極大地縮短了從數據獲取到洞察的時間周期,并支持探索性分析、機器學習、實時分析等高級用例。
相較于傳統數據倉庫,數據湖的“劍指”優勢體現在多個維度:
- 成本與可擴展性:利用廉價的云對象存儲,數據湖可以經濟高效地存儲海量數據,其近乎無限的擴展能力輕松應對數據量的爆炸式增長。
- 數據民主化與靈活性:打破了數據必須預先建模才能使用的壁壘,使得原始數據能夠被更廣泛的團隊訪問和利用,支持快速試錯和創新。
- 支持高級分析:作為機器學習、人工智能和實時流處理的理想數據源,數據湖為預測性分析和復雜的數據產品開發提供了肥沃的土壤。
- 避免數據孤島:通過集中存儲所有原始數據,數據湖有助于構建企業級的統一數據視圖,減少數據移動和冗余。
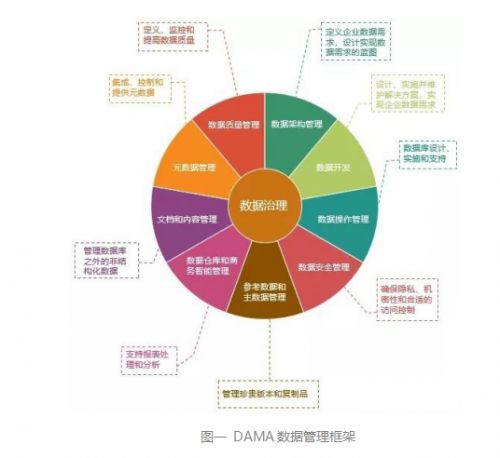
數據湖并非完美無缺。其最大的挑戰在于,若無妥善治理,極易退化為無人管理的“數據沼澤”——數據質量低下、難以發現、安全風險高、價值無法釋放。因此,下一代數據處理服務的核心任務,正是圍繞數據湖構建強大的治理、安全、元數據管理和處理能力。
這催生了湖倉一體(Lakehouse) 架構的興起,它旨在融合數據湖的靈活性與數據倉庫的事務管理、數據質量和性能優勢。現代數據處理服務(如Databricks、Snowflake、BigQuery等)正積極擁抱這一范式,提供統一的服務層,使得在同一個數據平臺上既能執行靈活的數據探索和機器學習,也能運行高性能的SQL分析和嚴格的商業智能報告。
數據湖及其演進形態將繼續引領數據處理服務的變革。其發展方向將聚焦于:
- 智能化治理:利用AI/ML自動進行數據分類、質量檢測、血緣追蹤和策略執行。
- 實時化融合:無縫集成流批處理,支持從實時事件中即時獲取洞察。
- 簡化與一體化:通過統一的SQL接口、自動化運維和Serverless計算,降低使用門檻,讓用戶更專注于數據價值本身。
數據湖已不僅僅是技術的迭代,它代表了一種面向未來的數據管理哲學——以原始數據為中心,通過強大、智能的數據處理服務賦能業務。它并非要完全取代數據倉庫,而是通過融合與進化,共同構建起更敏捷、更強大、更具成本效益的下一代企業數據基石。在這場變革中,誰能更好地駕馭數據湖,構建卓越的數據處理服務,誰就將在數據驅動的競爭中贏得先機。
如若轉載,請注明出處:http://m.babaf.cn/product/85.html
更新時間:2026-04-12 17:52:19